Introduction to Sorock
The name Sorock comes from Ebara Soroku who has established Azabu high school.
I respect him from my bottom of my heart.

Multi-Raft
Raft consensus algorithm in recent years is a widely used building block of distributed applications. The algorithm is about consensus on the sequence of log entries, which are applied to a state machine. When the two log entries are identical, then the resulting state is identical too. For such reason, it is also called replicated state machine.
The typical usage of the Raft algorithm is to implement a distributed key-value store. However, naive implementation will suffer from scalability issues due to the seriality of the algorithm. Let’s consider putting (k1,v1) and (k2,v2) in the data store, naive implementation can’t handle these two concurrently because the all write operations are serialized.
Sharding is a common solution to this kind of problem. If the k1 and k2 are enough distant in the key space, then the operations can be handled concurrently by sharded Raft clusters. TiKV is known to use this technique (ref).
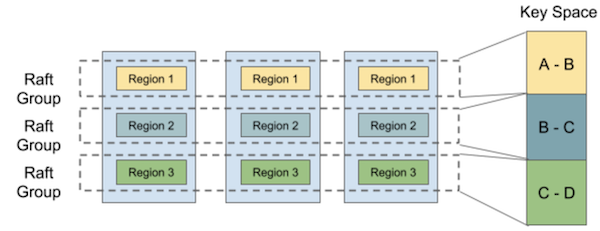
There are two ways in implementing a multi-raft. One is deploying multiple Raft clusters independently. One of the known problems of this approach is that resources like IP addresses or ports must be allocated per node to identify them. This introduces unnecessary complexity in deployment. Another problem is that shards can’t share the resources efficiently. In the implementation of a key-value store, the embedded datastore should be shared among the shards for efficient I/O such as write batching. For these problems, I will take the another approach.
Sorock implements in-process multi-raft. As the name implies, sorock allows you to place multiple Raft processes in a single gRPC server process. These Raft processes can form a Raft cluster on independent shards.
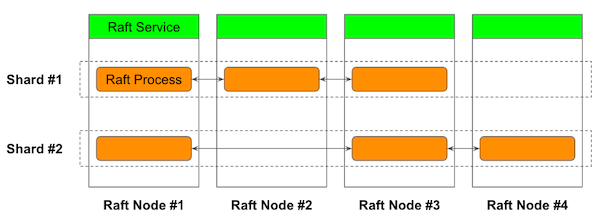
Heartbeat Multiplexing
In Raft, leader is responsible for periodically sending heartbeats to every followers to maintain the leadership. In Multi-Raft, without any optimization, the load from the the heartbeats will be non-negligible. To address this problem, we can make an optimization to reduce the heartbeat RPCs by multiplexing the heartbeats from different shards.
Problem of naive implementation
In the following diagram, we have two nodes (Node1 and Node2) and there are two shards. A Process with an asterisk (*) is a leader: P1 is sending heartbeats to the P3 and P2 to P4 as well. So there are two RPC messages sent from P1 to P3 and P2 to P4 independently.
graph LR
subgraph Node1
P1(P1*)
P2(P2*)
end
subgraph Node2
P3(P3)
P4(P4)
end
P1 -->|heartbeat| P3
P2 --> P4
Multiplexing heartbeats
To reduce the number of RPCs to only one, we will install multiplexer (Mux) and demultiplexer (Demux) in the nodes. The two heartbeats are buffered in the multiplexer and sent in a batched RPC to the destination node. In the destination node, the demultiplexer will split the batched RPC into individual heartbeats and send them to the corresponding processes.
graph LR
subgraph Node1
P1(P1*)
P2(P2*)
MUX(Mux)
end
subgraph Node2
DEMUX(Demux)
P3(P3)
P4(P4)
end
P1 --> MUX
P2 --> MUX
MUX --> DEMUX
DEMUX --> P3
DEMUX --> P4
In this case the reduction rate is 2.
Math: Reduction rate
What is the reduction rate in general? Let’s do some easy math.
Let’s consider there are N nodes and L shards. Each shard have K replication and leader processes are balanced among the nodes.
In this case, the total number of heartbeats sent in a period is LK. And the total directed paths connecting two nodes is N(N-1) and these heartbeats are evenly attributed to these paths. Therefore, the number of heartbeats sent in each path is LK/(N(N-1)) and this is the solution. For example, if there are 5 nodes and 1000 shards with 3 replication, the reduction rate is 150.
Batched Write
In Multi-Raft, multiple shards process write requests independently. Conceptually, each shard maintains its own log for entry insertion.
Having a physically independent log for each shard isn’t efficient as each write requires a transaction to persist the data on the storage.
However, an optimization technique called “batched write” can be used. Here, each shard maintains a virtual log, and the entries are temporarily queued in a shared queue. These queued entries are then processed in a single transaction, reducing the number of transactions.
This approach often presents a throughput versus latency dilemma. However, Sorock’s implementation increases throughput without much sacrificing latency.
graph LR
CLI(Client)
subgraph P1
T1(redb::Table)
end
subgraph P2
T2(redb::Table)
end
subgraph P3
T3(redb::Table)
end
subgraph Reaper
Q(Queue)
end
DB[(redb::Database)]
CLI -->|entry| T1
CLI --> T2
CLI --> T3
T1 -->|lazy entry| Q
T2 --> Q
T3 --> Q
Q -->|transaction| DB
Raft Process
The core of Multi-Raft is Raft process. Each Multi-Raft server has one or more Raft processes.
To implement Multi-Raft, Sorock implements Raft process as it is fully agnostic to detailed node communications through gRPC. Since the Raft process doesn’t know about the IO, we call it Pure Raft.
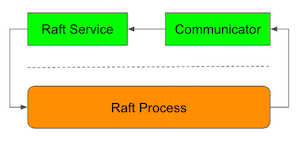
To make Raft process to communicate with other Raft processes
through network, RaftIO must be provided.
Everything about actual on-network communication is encapsulated under RaftIO.
#![allow(unused)]
fn main() {
impl RaftProcess {
pub async fn new(
app: impl RaftApp,
storage: &RaftStorage,
io: RaftIO,
) -> Result<Self> {
}Application State
Inside Raft Process, RaftApp and Log are most important data structures for application state.
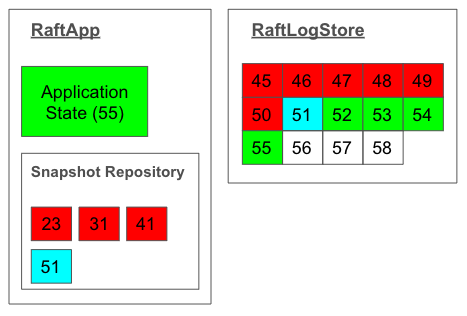
RaftApp
RaftApp is an abstraction that represents the application state and the snapshot repository.
The snapshot repository isn’t separated because the contents of the snapshot is
strongly coupled with the application state.
The application state can be updated by applying the log entries. In this figure, the lastly applied entry is of index 55.
RaftApp can arbitrarily generate a snapshot to compact the log.
When RaftApp makes a snapshot and stores it in the snapshot repository,
The newest snapshot is immediately picked up by an internal thread
to update the log (right in the figure) by replacing the snapshot entry.
In this figure, the snapshot index is 51.
Old snapshots will be garbage collected.
Snapshots might be fetched from other nodes. This happens when the Raft process is far behind the leader and the leader doesn’t have the log entries as they are previously garbage collected.
Log
In the figure, log entries from 45 to 50 are scheduled for garbage collection. Snapshot entry is of index 51 and it is guaranteed that the corresponding snapshot exists in the snapshot repository. 52 to 55 are applied. 56 or later are not applied yet: They are either uncommitted or committed.
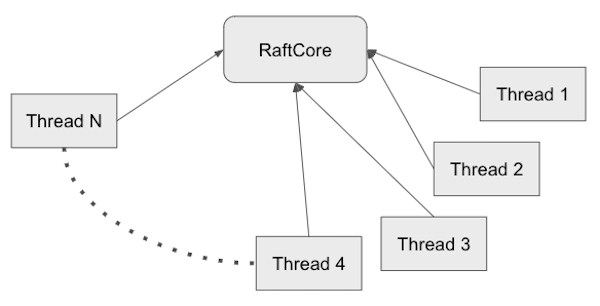
Multi Threading
Inside RaftProcess, there are so many looping threads to process concurrently.
Client Interaction
You can send application-defined commands to the Raft cluster.
Sorock distinguishes the command into two types: read-write (R/W) and read-only (R/O). The R/O command is called query and queries can be processed in parallel through the optimized path.
R/W commnand
R/W command is a normal application command which is inserted into the log to be applied later.
You can send a R/W command to the cluster with this API.
message WriteRequest {
uint32 shard_id = 1;
bytes message = 2;
string request_id = 3;
}
request_id is required to avoid doubly application. Let’s think about this scenario:
- The client sends a R/W command to add 1 to the value.
- The leader server replicates the command to the followers but crashes before application and response.
- The client resends the command to a new leader after a timeout.
- The result is adding 2 in total to the value while the expectation is only 1.
To avoid this issue, request_id is added to identify the commands.
R/O command
The R/O command can bypass the log because it is safe to execute the query after the commit index at time of query is applied. This is called read_index optimization.
You can send a R/O command to the cluster with the following API.
When read_locally is set to true, the request isn’t proxied to the leader but
processed locally.
message ReadRequest {
uint32 shard_id = 1;
bytes message = 2;
bool read_locally = 3;
}
Cluster Management
Single server change approach
There are two known approaches to change the cluster membership. One is by joint consensus and the other is what is called single server change approach. Sorock implements the second one because the thesis author recommends it.
This approach exploits the log replication mechanism in membership change
and therefore can be implemented as an extension of the normal log replication
by defining AddServer and RemoveServer commands.
From the admin client, the following API will add or remove a Raft process in the cluster.
message AddServerRequest {
uint32 shard_id = 1;
string server_id = 2;
}
message RemoveServerRequest {
uint32 shard_id = 1;
string server_id = 2;
}
Cluster bootstrapping
In Raft, any command is directed to the leader. Now the question is how to add a Raft process to the empty cluster.
The answer is so-called cluster bootstrapping. On receiving the AddServer command and the receiving node evaluates the cluster is empty, the node tries to form a new cluster with solely itself and immediately becomes a leader as a result of a self election.
Leadership
Command redirection
Raft is a leader-based consensus algorithm. Only a single leader can exist in the cluster at a time and all commands are directed to the leader.
In Sorock, if the receiving Raft process isn’t the leader, the command is redirected to the known leader.
Adaptive leader failure detection
Detecting the leader’s failure is a very important problem in Raft algorithm. The naive implementation written in thesis sends heartbeats to the followers periodically and followers can detect the leader’s failure by timeout. However, this approach requires the heartbeat interval and the timeout to be set properly before deployment. This brings another complexity. Not only that, these numbers can’t be fixed to a single value when the distance between nodes is heterogeneous in such as geo-distributed environment.
To solve this problem, Sorock uses an adaptive failure detection algorithm called Phi accrual failure detector. With this approach, users are free from setting the timing parameters.
Leadership transfer extension
In Multi-Raft, changing the cluster membership is not a rare case. An example of this case is rebalancing: To balance the CPU/disk usage between nodes, Raft processes may be moved to other nodes.
If the Raft process is to be removed as a leader, the cluster will not have a leader until a new leader is elected which causes downtime.
To mitigate this problem, the admin client can send a TimeoutNow command to any other Raft processes to forcibly start a new election (by promoting to a candidate).
message TimeoutNow {
uint32 shard_id = 1;
}
Development
Testing
cargo test -- --test-threads=1 to run the unit tests.
Benchmark
cargo run -p sorock-bench --release to run the Raft-level benchmark program.
Documentation
rake doc to start a local docs.rs server.
rake book to start a local mdbook server.